Last November, i spent a few days in Madrid to get a sneak peak at the Visualizar workshop at Medialab Prado. The projects that came out of the workshop are quite interesting and i’m currently interviewing some of the project leaders to get more insight on their own work, so stay tuned!
Medialab Prado is currently launching a new call for the Inclusiva-net. The workshop will explore the relationship between digital networks and physical space in the context of the increasingly widespread use of portable technology and Web applications in connection with the production and management of geographic information. Given the quality of Medialab Prado’s events, my advice would be “go ahead! answer the call!” The teachers will be Lalya Gaye (whom i interviewed over a year ago), Julian Oliver of the Selectparks fame, and Juan Mart??n Prada.
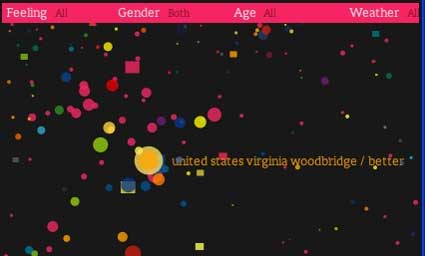
We Feel Fine
But let’s get back to the Visualizar workshop. As you might guess by its name, Visualizar explored the fascinating world of data visualization. In his introductory text , Jose Luis de Vicente, the curator of the workshop, described data visualization as a cross-discipline which uses the vast communicative power of images to offer a comprehensible explanation of the relationship among meaning, cause, and dependence that can be found among large abstract masses of information generated by scientific and social processes. Arising from the field of science two decades ago, InfoVis and DataVis combined strategies and techniques from statistics, graphic design and interaction and computer analysis to create a new communication model more suitable for clarification in the emerging Age of Complexity.
Jose Luis gave such a great talk about the subject last year that i’ve spent some time translating bits of it in english for you. The video is available online in spanish.
Visualising: tracing an aesthetics of data.
JL started by going back one century and a half ago. At the beginning of the end of the most powerful man of the time: Napoleon. The beginning of the end was the Russian campaign.

In 1812 by Illarion Prianishnikov (1840-1894)
On June 24, 1812, Napoleon’s Grande Arm??e of 691,501 men, the largest army assembled up to that point in European history, headed towards Moscow. Once they arrived in the capital, they found an empty city. It had been evacuated and stripped of all supplies. There was no official surrender and Napoleon felt that the situation robbed him of a traditional victory over the Russians.
The army had to retreat. Supplying the army on its way back was nearly impossible, mainly because of the harsh weather. The lack of grass weakened the army’s horses, almost all of which died or were eaten by starving soldiers. With no horses the French cavalry became footmen, cannons and wagons had to be abandoned, depriving the army of artillery and support convoys. As starvation and disease took their toll the desertion rate soared. Elements of the Grande Armee were defeated by the Russians at Vyazma, Krasnoi, and Polotsk. The crossing of the river Berezina was the final French catastrophe of the war, as two separate Russian armies inflicted horrendous casualties on the remnants of the Grande.
On December 14 1812 the Grande Arm??e was expelled from Russian territory. Only about 22,000 of Napoleon’s men survived the Russian campaign.

Minard’s map shows the advance of Napoleon’s Grande Arm??e into Russia in 1812. (full resolution)
What is one of the most epic moment in History has been turned by Charles Joseph Minard into a pioneering example of infoviz. In 1861 the French engineer published a Carte figurative des pertes successives en hommes de l’Arm??e Fran??aise dans la campagne de Russie 1812-1813, an information graph published in 1861 on the subject of Napoleon’s disastrous Russian campaign of 1812. The graph displays several variables in a 2D image:
– The thickness of the line indicates the strength of the army, with numbers indicating strength at critical points. From left to right : the thickest line on top is the army crossing the river with 422,000 men, advancing into Russian territory and stopping in Moscow with just 100,000 men. From right to left, returning west, and crossing back on river Niemen with 10,000. The numbers may go down or up, as the army joins with reserves (e.g. before river Berezina).
– The lower portion of the graph is to be read from right to left. It shows the temperature on the army’s return from Russia, in degrees below freezing on the w:en:R??aumur scale. (Multiply R??aumur temperatures by 1?? to get w:en:Celsius, e.g. ???30??R = ???37.5 ??C)]] Starting at ) degree in Moscow to minus 30 towards the end of the disastrous adventure.
This sole drawings translates in a very visual way the magnitude of the event and the way the campaign went from bad to worse over the course of a few months. The map embodies perfectly the power of dataviz, the communicative power of the image: using various factors, the map manages to translates in a sole image the importance of the fiasco that was the Russian campaign and how the disaster took place. One of the strength of information design and later of data visualization is that it can reduce the time necesssary for understanding a given event while at the same time it augments the capacity to grasp concrete phenomena of the past.
 The other story JL mentioned takes place in London around the same period and Steven Johnson wrote about it in his book The Ghost Map.
The other story JL mentioned takes place in London around the same period and Steven Johnson wrote about it in his book The Ghost Map.
The most devastating disease striking big European cities in the 19th century was cholera. Lacking garbage removal, clean water, sewers infrastructure, London was the perfect breeding ground for a disease no one knew how to cure. The consensus was that cholera was carried through the air, you could catch it by breathing “foul air” or coming into contact with someone suffering from cholera.
Physician and self-trained scientist John Snow was quite skeptical about that view and he set himself the task to prove it by investigating what could be the cause(s) of the lethal disease.
By talking to local residents (with the help of Reverend Henry Whitehead), he identified the source of the outbreak as the public water pump on Broad Street (now Broadwick Street). His studies of the pattern of the disease were convincing enough to persuade the local council to disable the well pump.
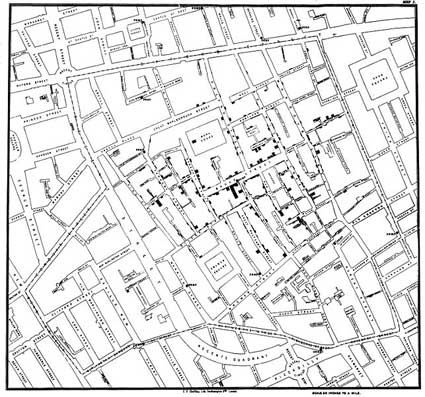
Original map by Dr. John Snow showing the clusters of cholera cases in the London epidemic of 1854
Snow used a spot map (back dots represents cases of cholera and crosses indicate a well) to study and illustrate how cases of cholera were centred around the pump. He also made a solid use of statistics to illustrate the connection between the quality of the source of water and cholera cases. He showed that companies taking water from sewage-polluted sections of the Thames delivered water to homes with an increased incidence of cholera.
Those two stories illustrate how an image is able to have meaningful patterns emerge from a mass of data.
Digital artist Ben Fry sees information design as the capacity of “thinking with the eyes”. An image can help us see things which we would otherwise no be able to fully understand, it externalizes our cognitive skills. The capacity of making meanings emerge through the power of vision is very high. Simple example: you’d take a piece of paper and a pen in order to break down the complexity of a mathematical problem. Similarly, the communicative qualities of a graphic design enables us to externalize a problem.
The communicative capacity of graphic design and the capacity to externalize the problems are united in this new forms of codifying information from an abstract mass of data to a spatial composition which are visually expressed.
So what is the state of the art today?
What happens when graphic designer, information designers, etc. start to use these tools in a social context?
A first example concerning the crisis between Lebanon and the US in the Summer of 2006 when Britain, Israel and the US were left exposed for refusing to comply with UN’s demand to end to hostilities. The news appeared in most newspapers around the world. Yet one of them came up with a visually striking representation of the issue:

Middle East Crisis: Who backs an immediate ceasefire? (see cover of the newspaper here and here)
The impact of the news is much different if we put it into words or if it is translated in a visual code. Newspapers are making an increasing use of data visualization.
Of course, there are many other examples to be found in the artistic and scientific sphere.
Examples:
Inequality, created by Josh On using Processing, demonstrates in a crystal clear way that while in 1960 US CEOs were paid 41 times more than the average worker, in 2001 their pay was 411 times higher than the average worker.


If you were to put the same data on a traditional statistical graphic, you’d get the same information. Minus the immediate appeal and the interactivity.
(artificial.dk has a great interview with the artist btw and there’s a video of one of his talk at one of The Influencers conferences).
Information design has its limits: the dataset is quite static, the assembly of data has a certain level of simplicity and there is no interaction. That’s where enters a new discipline which will influence cartography, graphic design and other transversal disciplines.
Starting in the ’90s a new class of visualization practitioners, half way between the analysis of digital information and strategies of representation, emerge and propose examples where data visualization is not only applied to analyze abstract data but where it also proposes other levels of interpretation and readings.
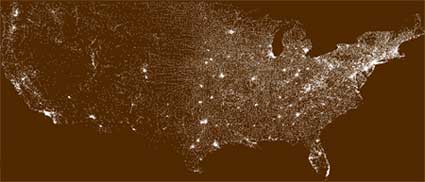
Example. Ben Fry wanted to find an answer to a simple question: “How exactly are zip codes assigned across the U.S.?” His answer is zipdecode which is as simple as the postal code system might appear to be complex.
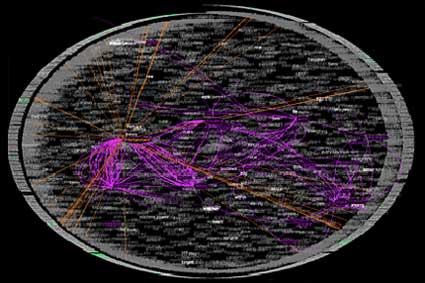
TextArc, by Bradford Paley who used to be the designer responsible for the visualization system at Wall Street, shows quite well how the infoviz genre is hybrid and multi-disciplinary. TextArc is a fascinating visual representation of a text –in this case Alice in Wonderland and Hamlet— on a single page. Paley dismounted the novel and turned it into a spatial structure where the position of the elements indicate their importance and the lines which circulate around them trace the connections that link the words.
Other example, Color Code an interactive treemap displaying about over 33,000 English nouns, each of them is represented by a rectangle, which has been assigned a color based on the average of the colors found via an image search for that noun. in addition, the words are clustered so that similar words are near each other.

JL then showed one of my favourite infoviz projects ever: Marcos Weskamp‘s Newsmap.
The application visually reflects the constantly changing landscape of the Google News news aggregator. dividing information into easily recognizable bands which, when presented together, reveal underlying patterns in news reporting across cultures and within news segments in constant change around the globe.
The aesthetical choices have a semantic translation, they correspond to different levels of meaning to organize the information in a certain way.

10×10, by Jonathan Harris, is an interactive and ever-changing snapshot of the words and pictures that define the time. The system monitors leading international news sources and every hour, it collects the 100 words and pictures that are deemed most important on a global scale, and presents them as a single image. Over the course of days, months, and years, 10×10 leaves a trail of these hourly statements which, stitched together side by side, form a patchwork of human life.
JL pointed out that the representation of a data set is always arbitrary. There are obviously many other ways to represent a set of data and the relationship that emerge between them.
Besides, data visualization is the visual embodiment, the translation to another language of a series of process which some call data mining, the science of extracting useful information from large amounts of data or from a database. Data mining is being used as a technique for investigation which slowly moves from the scientific sphere to a more social and cultural oriented level.
 Freakonomics: A Rogue Economist Explores the Hidden Side of Everything, a book available at any airport and published in 2005 by economist Steven Levitt and New York Times journalist Stephen J. Dubner. In the book Levitt uses techniques of statistical analysis to give answers to a series of (sometimes quite surprising) questions. The book has raised debate, especially regarding the chapter which explains how criminality in New York fell sharply in the ’90s. In his view, the main factor which justifies the drop of violence is the legalization of abortion in the ’70s.
Freakonomics: A Rogue Economist Explores the Hidden Side of Everything, a book available at any airport and published in 2005 by economist Steven Levitt and New York Times journalist Stephen J. Dubner. In the book Levitt uses techniques of statistical analysis to give answers to a series of (sometimes quite surprising) questions. The book has raised debate, especially regarding the chapter which explains how criminality in New York fell sharply in the ’90s. In his view, the main factor which justifies the drop of violence is the legalization of abortion in the ’70s.
Other example: with the Enron Explorer, Trampoline engineers offered access to the 200,000 Enron internal emails released during the fraud investigation. The system generates a visualisation of each employee’s social network and allows users to explore the way those social networks were somehow responsible for factors which led to the fall of the American energy company.
the case of Enron marks a transition in the journalistic techniques from an era where the focus was on telling facts to an era focused on filtrating data. The Watergate scandal emerged because a hidden information was discovered. The case of Enron was different, it was a journalist who used public data, started analyzing them and realized at some point that the relationships between the data didn’t match the activities that Enron was supposed to carry out.
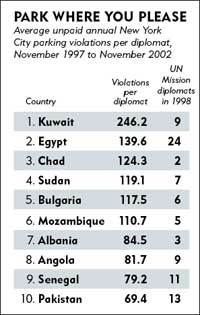
Another very simple example shows how to tell a story by using a set of data. Corruption is believed to be a major factor impeding economic development, but the importance of legal enforcement versus cultural norms in controlling corruption is poorly understood. To disentangle these two factors, two researchers went through the stationing of thousands of diplomats from around the world in New York City. Diplomatic immunity means there were not fine for parking violations, the researchers were therefore left to examine the role of cultural norms alone (at least that’s what they believe). The result of their investigation appears on the image on the left.
To give even more strength to the usual cultural stereotypes, the diplomats who receive the smallest number of fines come from Norway, Denmark, Sweden, etc.
Another case is the one of a journalist from Wired who thought that there might be some relationship appearing between pedophile (data on convicted sex offenders are public in the United States) and users of MySpace. He thus wrote a script that ferreted out registered sex-offenders on the social platform. Some of the offenders he found were just hanging out with their friends and families, but 3 of them were actively soliciting sex from children — his work led to the arrest of one such, Andrew Lubrano. The code has been made available.

A famous fashion to manage data is the tag cloud. Example, the US Presidential Speeches Tag Cloud which gives an overview of the words that US presidents used most frequently in their speeches, showing which issues they deemed important over time.
Another area where infoviz can do wonder is when it plays the role of sociograms, unveiling the relationship between people and the kind of structures that emerge from these relationships.
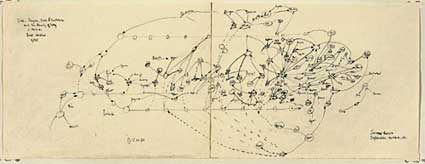
Artist Mark Lombardi was fascinated both by complex social structures and conspirations and he merged both passion in his famous Conspiracy Maps which analyzed affairs such as The Watergate, the collapse of the Vatican bank and the Iran-Contra scandal.
Which brings to our mind one of the most famous piece of media art of the past 15 years: They Rule by Josh On. The application reveals some of the relationships of the US ruling class, how the boards of some of the most powerful U.S. companies share many of the same directors, how some individuals sit on 5, 6 or 7 of the top 500 companies. It allows users to browse through these interlocking directories and run searches on the boards and companies.
The strength of a work like They Rule is not that it “gives you the solution” or tells you whether the people sitting at the boards hate each other or are friends but it artistically shows levels of complexities of our reality which would otherwise be difficult to comprehend.

World Processor by Ingo G??nther projects on physical world globes the geographical distribution of various social, environmental and political world parameters: international migrations, countries debts, wealth distribution, countries with biggest emission of CO2, etc.
Chicago Crime database projects on Google Maps data about criminality in the country as discovered by the police.
The Database of Intentions (as coined by John Battellle). An important change in the creation, classification and dissemination of data is that it is no longer a result of scientific, economical or statistical processes. Instead it has become a social reality. Each of us has become a generator of data. We can thanks web 2.0 for that and also search engines. Each time we look for a word on a search engine we obtain information at the same time as that search engine gets information from us: what we want, what we look for, what interests us, what scares us, what worries us, etc.
A sad example is how AOL released massive amounts of data concerning the queries made by its users. They later apologized but it was way too late.

Listening Post by Mark Hansen and Ben Rubin poetically give a face to the flow of data. The installation culls text fragments in real time from chat rooms, bulletin boards and other public forums. The texts are read by a voice synthesizer, and displayed across a suspended grid of more than 200 electronic screens.
Digg Labs, developed by Stamen, translates visually and in real time the activity of the social community.
But how do you classify the quality of a social activity?
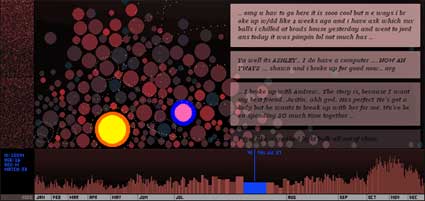
Golan Levin showed in the brilliant The Dumpster how to visualize the romantic breakups of teenagers.
A somewhat similar and more ambitious project We Feel Fine, by Jonathan Harris and Sep Kamvar, investigates human emotions by harvesting data about web user’ moods and feelings from weblogs. A script searches newly posted blog entries for occurrences of “I feel” & “I am feeling”, records the full sentence & identifies the “feeling” expressed in that sentence (e.g. sad, happy, depressed, etc.).
JL ended by an anecdote about They Rule. Apparently two kind of people check out TR. The web users who is curious about the project but also the very people who are part of TR, the board members who use it see how they could reach another person, who in their entourage is connected to someone who is connected to that person.
However, the main danger of the fascinating images generated by these data designers is to believe that reality can be defined and limited by an image. That they suffice to grasp and interpret reality.
Related entries: A series of posts about one Medialab Prado’s latest workshop, Interactivos?, Interview with Jose Luis de Vicente.













{kind=link}
{kind=link}
{kind=link}
{kind=link}